架构
MIMO
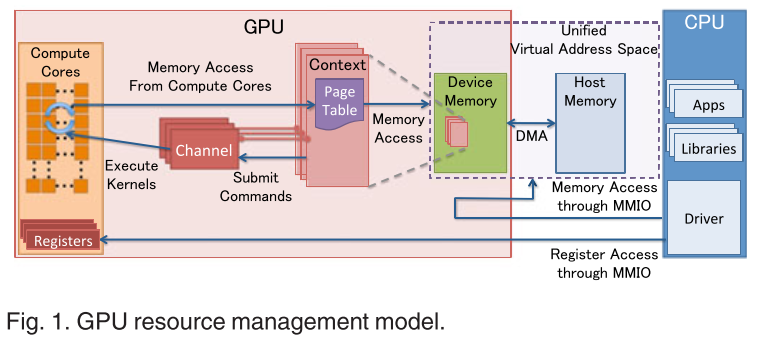
CPU通过MMIO与GPU进行通信。
支持 DMA 硬件引擎传输大量数据,但应通过 MMIO 写入命令。
GPU context
代表GPU当前状态,每个context有自己的page table,多个context可以同时共存(可以视为类似进程的概念?)
Page Table
gpu页表,和CPU的page table功能一样,用于VA到PA的映射,访问GPU的地址空间
驻留在 GPU 内存中,其物理地址位于 GPU 通道描述符中。
所有通过通道提交的命令和程序都在相应的GPU虚拟地址空间中执行。
GPU页表不仅将GPU虚拟地址翻译成GPU设备物理地址,而且将其翻译成主机物理地址。这使得GPU页表能够将GPU内存和主机主内存统一到统一的GPU虚拟地址空间中 。
GPU Channel 。
任何操作(例如启动内核)都是由 CPU 发出的命令驱动的。
命令流被提交到称为 GPU Channel的硬件单元。 每个 GPU 上下文可以有一个或多个 GPU 通道。每个GPU上下文包含GPU通道描述符(每个描述符被创建为GPU内存中的内存对象)。
每个GPU通道描述符存储通道的设置,其中包括页表
每个 GPU 通道都有一个专用的命令缓冲区,该缓冲区分配在 CPU 通过 MMIO 可见的 GPU 内存中。
PCIe 条 。
PCIe 的基址寄存器(BAR)作为 MMIO 的窗口,在 GPU 启动时进行配置。
GPU 控制寄存器和 GPU 内存孔径映射到 BAR 上。
设备驱动程序使用此映射的 MMIO 窗口来配置 GPU 并访问 GPU 内存。
CPU和GPU通信主要有几下几种方式:
通过PCIe BAR空间映射出来的寄存器
通过PCIe BAR空间把GPU的内存映射到CPU的地址空间中
通过GPU的页表把CPU的系统内存映射到GPU的地址空间中
通过MSI中断
gpu申请内存/释放 当我们用ioctl 指定mem_alloc时,最终会从linux 系统的内存管理模块分配出内存,分配的内存返回给gpu驱动后,可以写入gpu执行所需的数据(job,顶点,纹理之类的),这些数据的写入是用户通过ioctl完成的,当数据写入完成后,就可以trigger kernel driver来执行GPU硬件工作,这个时候GPU硬件需要读取前面准备好的数据,这时需要借助GPU MMU来完成地址的转换工作,否则GPU没有办法完成数据的正确读取。释放的话就是alloc_pages 对应的 free_pages
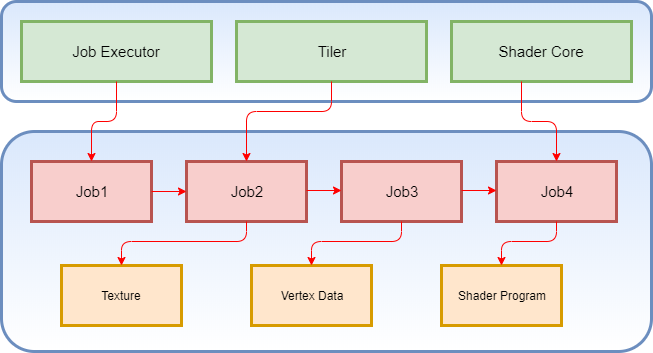
job创建、提交与执行 //此处没写好
当用户向内存填充完数据之后,用户通过ioctl 将该内存 “提交” 给gpu,视作一个job,具体的其实是个建立映射的过程,即让gpu 页表可以映射到该内存。
Mali GPU Job可以理解成GPU硬件能理解的IR(中间语言),gpu driver将上层user的api(ioctl)转化为job的描述,然后将job的内存地址告诉gpu硬件,gpu硬件的job executor 就开始解析这些job,从而驱动gpu硬件完成相应工作。
数据结构/接口 mali 驱动为用户提供的部分接口如下:
序号
命令
功能
1
KBASE_IOCTL_MEM_ALLOC
分配内存区域,内存区域中的页会映射到GPU中,可选择同时映射到CPU
2
KBASE_IOCTL_MEM_QUERY
查询内存区域属性
3
KBASE_IOCTL_MEM_FREE
释放内存区域
4
KBASE_IOCTL_MEM_SYNC
同步数据,使得CPU和GPU可以及时看到对方操作结果
5
KBASE_IOCTL_MEM_COMMIT
改变内存区域中页的数量
6
KBASE_IOCTL_MEM_ALIAS
为某个内存区域创建别名,即多个GPU虚拟地址指向同一个区域
7
KBASE_IOCTL_MEM_IMPORT
将CPU使用的内存页映射到GPU地址空间中
8
KBASE_IOCTL_MEM_FLAGS_CHANGE
改变内存区域属性
gpu driver 用 region来描述一段内存区域,一段内存区域会有用于映射该区域时gpu/cpu用于内存映射的内存分配对象 即 cpu_alloc,gpu_alloc
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 struct kbase_va_region { struct rb_node rblink ; struct list_head link ; struct rb_root *rbtree ; u64 start_pfn; size_t nr_pages; size_t initial_commit; unsigned long flags; size_t extent; struct kbase_mem_phy_alloc *cpu_alloc ; struct kbase_mem_phy_alloc *gpu_alloc ; struct list_head jit_node ; u16 jit_usage_id; u8 jit_bin_id; int va_refcnt; };
可以看到通过start_pfn,nr_pages 即可得出region的范围
而更具体的物理页描述由struct kbase_mem_phy_alloc 描述
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 struct kbase_mem_phy_alloc { struct kref kref ; atomic_t gpu_mappings; atomic_t kernel_mappings; size_t nents; struct tagged_addr *pages ; struct list_head mappings ; struct list_head evict_node ; size_t evicted; struct kbase_va_region *reg ; enum kbase_memory_type type ; struct kbase_vmap_struct *permanent_map ; unsigned long properties; union { #if defined(CONFIG_DMA_SHARED_BUFFER) struct { struct dma_buf *dma_buf ; struct dma_buf_attachment *dma_attachment ; unsigned int current_mapping_usage_count; struct sg_table *sgt ; } umm; #endif struct { u64 stride; size_t nents; struct kbase_aliased *aliased ; } alias; struct { struct kbase_context *kctx ; size_t nr_struct_pages; } native; struct kbase_alloc_import_user_buf { unsigned long address; unsigned long size; unsigned long nr_pages; struct page **pages ; u32 current_mapping_usage_count; struct mm_struct *mm ; dma_addr_t *dma_addrs; } user_buf; } imported; };
映射流程 KBASE_IOCTL_MEM_ALLOC 以及 KBASE_IOCTL_MEM_IMPORT 都可以映射内存页到gpu中,这里我们先以 KBASE_IOCTL_MEM_IMPORT为例
传参/返回值:
1 2 3 4 5 6 7 8 9 10 11 12 union kbase_ioctl_mem_alloc { struct { __u64 va_pages; __u64 commit_pages; __u64 extent; __u64 flags; } in; struct { __u64 flags; __u64 gpu_va; } out; };
其调用链大致如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 drivers/gpu/arm/b_r32p0/mali_kbase_core_linux.c kbase_api_mem_alloc () | | BASE_MEM_SAME_VA | |-> kbase_mem_alloc () | |-> kbase_check_alloc_flags () | |-> kbase_alloc_free_region () | |-> kbase_reg_prepare_native () | |-> kbase_alloc_phy_pages () | |-> kctx->pending_regions[cookie_nr] = reg
在kbase_api_mem_alloc()函数中,若是64位进程的话,则指定 flags |= BASE_MEM_SAME_VA ,含义是CPU和GPU使用相同的虚拟地址(数值上)。
kbase_mem_alloc()首先调用kbase_check_alloc_flags()来检查应用传入的flags是否合法 ,主要的规则是
1 2 3 1 内存区域必须映射到GPU中,映射属性可以是只读、仅可写、可读写 2 CPU和GPU至少有一方是可以读内存区域的,否则分配物理页没有意义 3 同样,至少有一方是可以写内存区域的,否则分配物理页没有意义
然后调用kbase_alloc_free_region()来创建一个region
主要是通过kzalloc分配region对象,初始化相关元素
1 2 3 4 5 6 7 8 new_reg->va_refcnt = 1 ; new_reg->cpu_alloc = NULL ; new_reg->gpu_alloc = NULL ; new_reg->rbtree = rbtree; new_reg->flags = zone | KBASE_REG_FREE; new_reg->flags |= KBASE_REG_GROWABLE; new_reg->start_pfn = start_pfn; new_reg->nr_pages = nr_pages;
kbase_reg_prepare_native()函数则主要负责初始化reg->cpu_alloc和reg->gpu_alloc
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 reg->cpu_alloc = kbase_alloc_create(kctx, reg->nr_pages, KBASE_MEM_TYPE_NATIVE); reg->cpu_alloc->imported.native.kctx = kctx; if (kbase_ctx_flag(kctx, KCTX_INFINITE_CACHE) && (reg->flags & KBASE_REG_CPU_CACHED)) { reg->gpu_alloc = kbase_alloc_create(kctx, reg->nr_pages, KBASE_MEM_TYPE_NATIVE); if (IS_ERR_OR_NULL(reg->gpu_alloc)) { kbase_mem_phy_alloc_put(reg->cpu_alloc); return -ENOMEM; } reg->gpu_alloc->imported.native.kctx = kctx; } else { reg->gpu_alloc = kbase_mem_phy_alloc_get(reg->cpu_alloc); }
然后调用kbase_alloc_phy_pages()为reg->cpu_alloc分配物理页,该函数会调用->kbase_alloc_phy_pages_helper()->kbase_mem_pool_alloc_pages()->…->alloc_page(),向buddy system请求物理页。
之后将reg挂载到kctx->pending_regions数组中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 if (*flags & BASE_MEM_SAME_VA) { unsigned long prot = PROT_NONE; unsigned long va_size = va_pages << PAGE_SHIFT; unsigned long va_map = va_size; unsigned long cookie, cookie_nr; unsigned long cpu_addr; if (!kctx->cookies) { dev_err(dev, "No cookies available for allocation!" ); kbase_gpu_vm_unlock(kctx); goto no_cookie; } cookie_nr = __ffs(kctx->cookies); kctx->cookies &= ~(1UL << cookie_nr); BUG_ON(kctx->pending_regions[cookie_nr]); kctx->pending_regions[cookie_nr] = reg; cookie = cookie_nr + PFN_DOWN(BASE_MEM_COOKIE_BASE); cookie <<= PAGE_SHIFT; if (kctx->api_version < KBASE_API_VERSION(10 , 1 ) || kctx->api_version > KBASE_API_VERSION(10 , 4 )) { *gpu_va = (u64) cookie; return reg; }
可以看出来,此处并没有建立gpu_va到物理页的映射,gpu_va值是一个cookie,这个值将会在真正建立映射时被使用。
如何建立映射?gpu驱动自定义了kbase_mmap函数作为mmap函数,该函数主要流程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 kbase_mmap(struct file *file, struct vm_area_struct *vma) | | BASE_MEM_SAME_VA | |-> kbase_region_tracker_find_region_enclosing_address() | |-> kbase_cpu_mmap() | |-> kbase_get_cpu_phy_pages() | |-> vm_insert_pfn() | |-> kbase_mem_phy_alloc_get() | |-> kctx->pending_regions[cookie_nr] = reg
调用 kbase_region_tracker_find_region_enclosing_address
1 2 reg = kbase_region_tracker_find_region_enclosing_address(kctx, (u64)vma->vm_pgoff << PAGE_SHIFT); 找到gpu_va(也就是那个cookie所对应的region)
建立映射
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 if (!kaddr) { unsigned long addr = vma->vm_start + aligned_offset; vma->vm_flags |= VM_PFNMAP; for (i = 0 ; i < nr_pages; i++) { phys_addr_t phys; phys = as_phys_addr_t (page_array[i + start_off]); err = vm_insert_pfn(vma, addr, PFN_DOWN(phys)); if (WARN_ON(err)) break ; addr += PAGE_SIZE; } } map ->region = kbase_va_region_alloc_get(kctx, reg); map ->free_on_close = free_on_close; map ->kctx = kctx; map ->alloc = kbase_mem_phy_alloc_get(reg->cpu_alloc); map ->count = 1 ; if (reg->flags & KBASE_REG_CPU_CACHED) map ->alloc->properties |= KBASE_MEM_PHY_ALLOC_ACCESSED_CACHED; list_add(&map ->mappings_list, &map ->alloc->mappings);
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 vma的flag位设置,可以看出子进程是不共享该gpu内存的 #if (LINUX_VERSION_CODE >= KERNEL_VERSION(3, 7, 0)) vma->vm_flags |= VM_DONTCOPY | VM_DONTDUMP | VM_DONTEXPAND | VM_IO; #else vma->vm_flags |= VM_DONTCOPY | VM_DONTEXPAND | VM_RESERVED | VM_IO;
与直接分配物理页不同,KBASE_IOCTL_MEM_IMPORT可以导入cpu的地址到gpu
漏洞点:当没有KBASE_REG_SHARE_BOTH标志,通过提交一个列出该区域作为外部资源的原子作业,临时填充.pages数组,将页面映射到Mali的主机用户空间映射中(该映射为VM_PFNMAP),然后让作业完成,这会导致Mali在不清除主机用户空间映射中相应PTE的情况下释放.pages数组中页面的引用。
我不确定正确的修复方法是禁止从没有KBASE_REG_SHARE_BOTH标志的KBASE_MEM_TYPE_IMPORTED_USER_BUF区域中导入页面,还是确保在其后备内存消失时正确清除主机虚拟映射,或者两者都需要?我还没有详细研究其他区域类型是否存在类似问题。
Author:
7r1p13J
License:
Copyright (c) 2019 CC-BY-NC-4.0 LICENSE