enummigratetype { MIGRATE_UNMOVABLE, //不可迁移页 MIGRATE_MOVABLE, //可迁移页 MIGRATE_RECLAIMABLE,//可回收页 MIGRATE_PCPTYPES, /* the number of types on the pcp lists */ MIGRATE_HIGHATOMIC = MIGRATE_PCPTYPES, #ifdef CONFIG_CMA /* * MIGRATE_CMA migration type is designed to mimic the way * ZONE_MOVABLE works. Only movable pages can be allocated * from MIGRATE_CMA pageblocks and page allocator never * implicitly change migration type of MIGRATE_CMA pageblock. * * The way to use it is to change migratetype of a range of * pageblocks to MIGRATE_CMA which can be done by * __free_pageblock_cma() function. What is important though * is that a range of pageblocks must be aligned to * MAX_ORDER_NR_PAGES should biggest page be bigger than * a single pageblock. */ MIGRATE_CMA, #endif #ifdef CONFIG_MEMORY_ISOLATION MIGRATE_ISOLATE, /* can't allocate from here */ #endif MIGRATE_TYPES };
structpage *__alloc_pages(gfp_tgfp, unsignedintorder, intpreferred_nid, nodemask_t *nodemask) { structpage *page; unsignedint alloc_flags = ALLOC_WMARK_LOW; gfp_t alloc_gfp; /* The gfp_t that was actually used for allocation */ structalloc_contextac = { };
/* * There are several places where we assume that the order value is sane * so bail out early if the request is out of bound. */ if (unlikely(order >= MAX_ORDER)) { WARN_ON_ONCE(!(gfp & __GFP_NOWARN)); returnNULL; }
gfp &= gfp_allowed_mask; /* * Apply scoped allocation constraints. This is mainly about GFP_NOFS * resp. GFP_NOIO which has to be inherited for all allocation requests * from a particular context which has been marked by * memalloc_no{fs,io}_{save,restore}. And PF_MEMALLOC_PIN which ensures * movable zones are not used during allocation. */ gfp = current_gfp_context(gfp); alloc_gfp = gfp; if (!prepare_alloc_pages(gfp, order, preferred_nid, nodemask, &ac, &alloc_gfp, &alloc_flags)) returnNULL;
/* * Forbid the first pass from falling back to types that fragment * memory until all local zones are considered. */ alloc_flags |= alloc_flags_nofragment(ac.preferred_zoneref->zone, gfp);
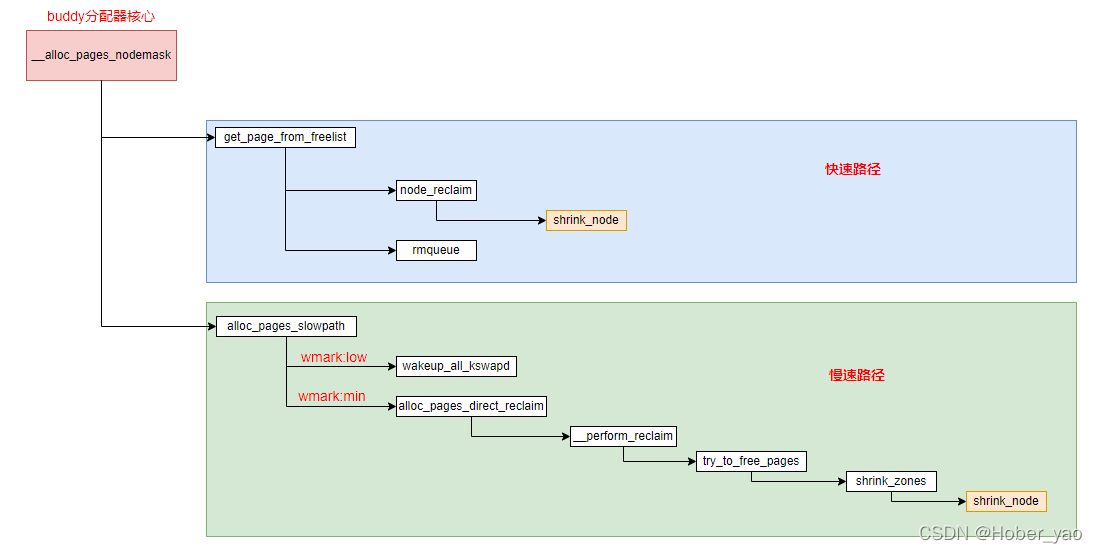
/* First allocation attempt */ page = get_page_from_freelist(alloc_gfp, order, alloc_flags, &ac); if (likely(page)) goto out;
alloc_gfp = gfp; ac.spread_dirty_pages = false;
/* * Restore the original nodemask if it was potentially replaced with * &cpuset_current_mems_allowed to optimize the fast-path attempt. */ ac.nodemask = nodemask;
而NODEMASK 作为内核基础数据结构,常用于统计当前 Online/Possible Online NUMA NODE 的数量、判断 NUMA NODE 是否包含内存、判断 NUMA NODE 是否与 CPU 进行绑定等,NODEMASK 作为 NUMA 子系统不可或缺的一部分,为内核和其他子系统提供了 NUMA NODE 的多种信息,首先来看一下 NODEMASK 定义:
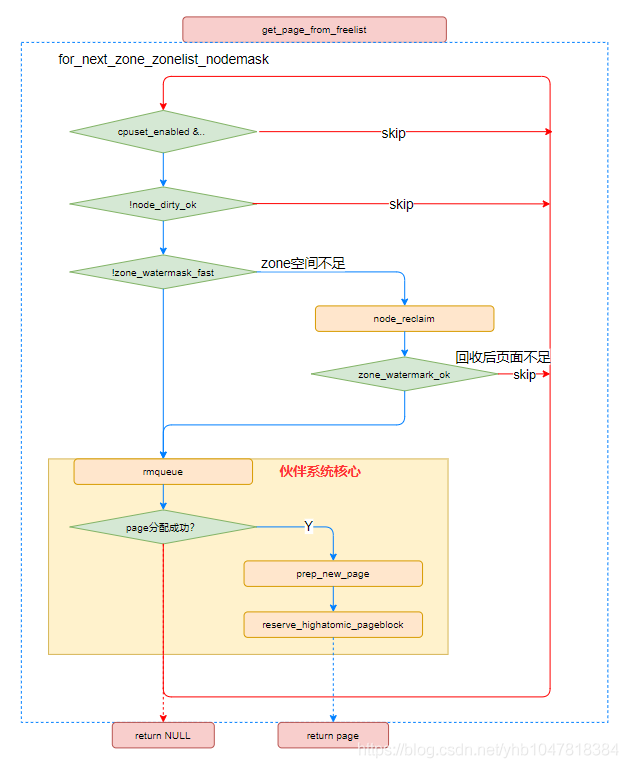
#ifdef CONFIG_DEFERRED_STRUCT_PAGE_INIT /* * 该 zone 的水位线失败, 但若其包含了 deferred pages, * 则我们会看该 zone 是否还能再进行扩展 */ if (static_branch_unlikely(&deferred_pages)) { if (_deferred_grow_zone(zone, order)) goto try_this_zone; } #endif /* Checked here to keep the fast path fast */ BUILD_BUG_ON(ALLOC_NO_WATERMARKS < NR_WMARK); if (alloc_flags & ALLOC_NO_WATERMARKS)//不需要检查水位线的话 直接从该zone分配 goto try_this_zone;
if (!node_reclaim_enabled() || !zone_allows_reclaim(ac->preferred_zoneref->zone, zone)) continue; //进行页面回收 ret = node_reclaim(zone->zone_pgdat, gfp_mask, order); switch (ret) { case NODE_RECLAIM_NOSCAN: /* 不做扫描 */ continue; case NODE_RECLAIM_FULL: /* 扫描了但不可回收 */ continue; default: /* 是否回收足够的页 */ if (zone_watermark_ok(zone, order, mark, ac->highest_zoneidx, alloc_flags)) goto try_this_zone;
staticstruct page *rmqueue_pcplist(struct zone *preferred_zone, struct zone *zone, unsignedint order, gfp_t gfp_flags, int migratetype, unsignedint alloc_flags) { structper_cpu_pages *pcp; structlist_head *list; structpage *page; unsignedlong flags;
local_lock_irqsave(&pagesets.lock, flags);
/* * On allocation, reduce the number of pages that are batch freed. * See nr_pcp_free() where free_factor is increased for subsequent * frees. */ pcp = this_cpu_ptr(zone->per_cpu_pageset); pcp->free_factor >>= 1; list = &pcp->lists[order_to_pindex(migratetype, order)];//选择list page = __rmqueue_pcplist(zone, order, migratetype, alloc_flags, pcp, list); local_unlock_irqrestore(&pagesets.lock, flags); if (page) { __count_zid_vm_events(PGALLOC, page_zonenum(page), 1); zone_statistics(preferred_zone, zone, 1); } return page; }
staticintrmqueue_bulk(struct zone *zone, unsignedint order, unsignedlong count, struct list_head *list, int migratetype, unsignedint alloc_flags) { int i, allocated = 0;
/* * local_lock_irq held so equivalent to spin_lock_irqsave for * both PREEMPT_RT and non-PREEMPT_RT configurations. */ spin_lock(&zone->lock); for (i = 0; i < count; ++i) { structpage *page = __rmqueue(zone, order, migratetype, alloc_flags); if (unlikely(page == NULL)) break;
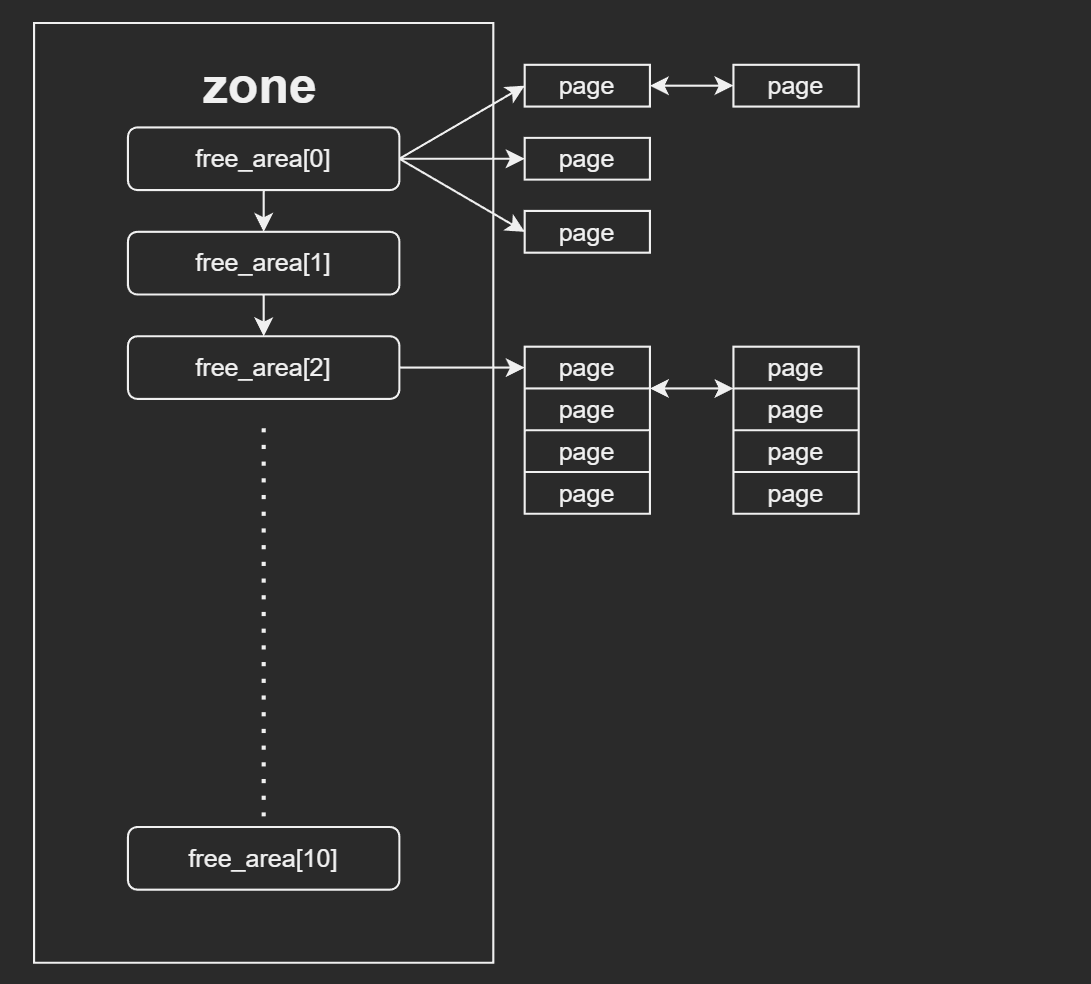
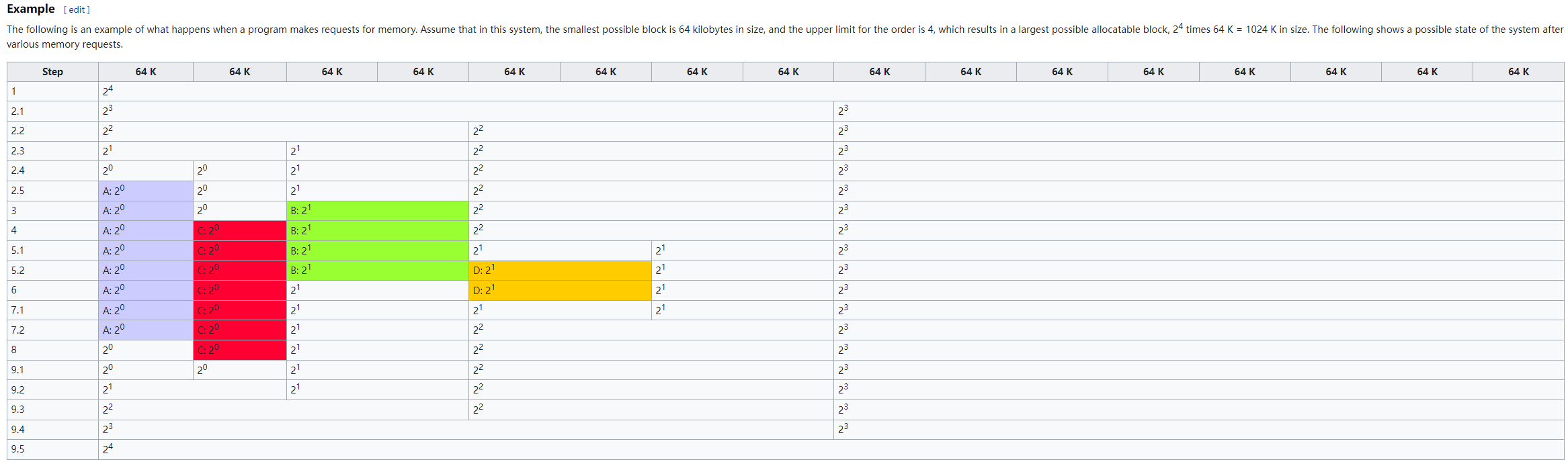
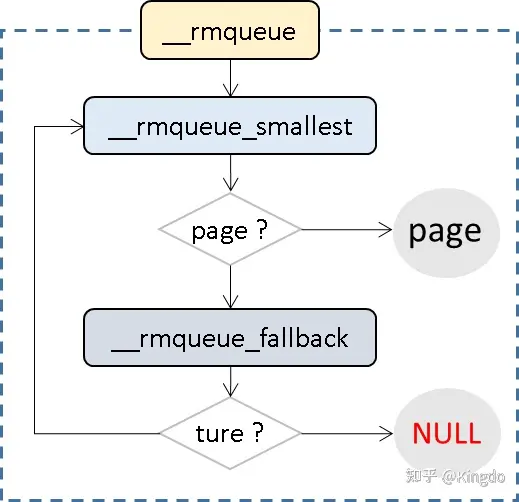
/* Find a page of the appropriate size in the preferred list */ for (current_order = order; current_order < MAX_ORDER; ++current_order) { area = &(zone->free_area[current_order]); page = get_page_from_free_area(area, migratetype);//从指定迁移类型的list中找到page,如果失败,则寻找的order++; if (!page) continue; del_page_from_free_list(page, zone, current_order);//负责将其list中拿走,操作包括list_del,list的计数--等; expand(zone, page, order, current_order, migratetype);//负责拆分的函数,即如果从odrer较大的list中选择了一一组page进行拆分,那么拆分后剩余的page将被添加到较低order的list中 set_pcppage_migratetype(page, migratetype); return page; }