物理内存组织与架构
源码均参考5.17版本的内核
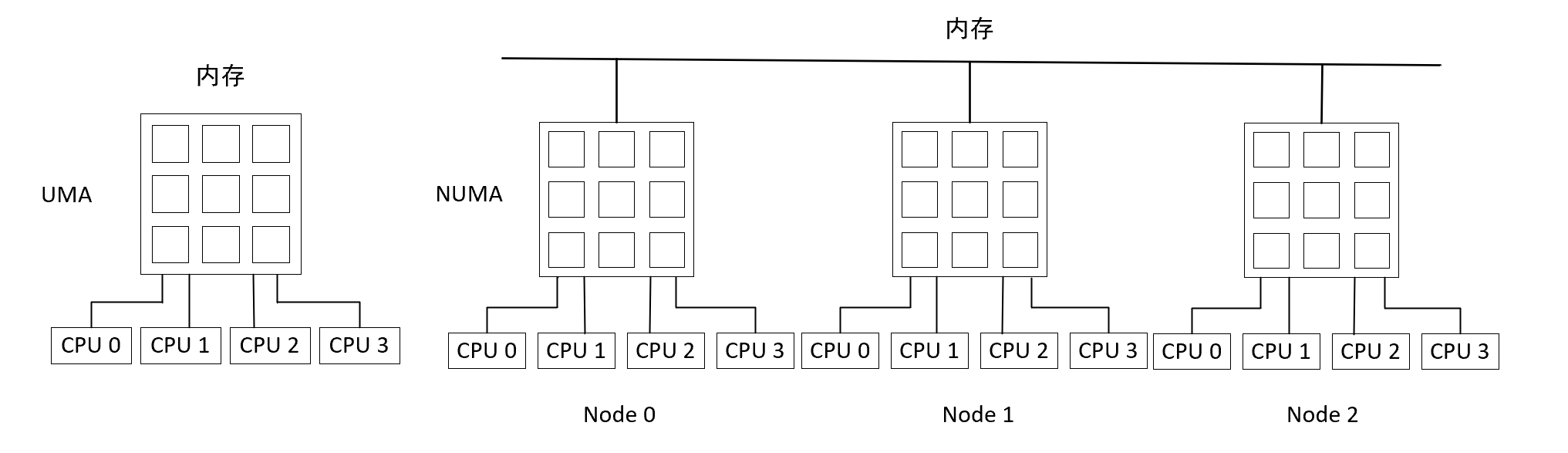
NUMA与UMA
共享存储型多处理机有两种模型
- 均匀存储器存取(Uniform-Memory-Access,简称UMA)模型
- 非均匀存储器存取(Nonuniform-Memory-Access,简称NUMA)模型
UMA模型
物理存储器被所有处理机均匀共享。所有处理机对所有存储字具有相同的存取时间,这就是为什么称它为均匀存储器存取的原因。每台处理机可以有私用高速缓存,外围设备也以一定形式共享。
NUMA模型
NUMA模式下,处理器被划分成多个”节点”(node), 每个节点被分配有的本地存储器空间。 所有节点中的处理器都可以访问全部的系统物理存储器,但是访问本节点内的存储器所需要的时间,比访问某些远程节点内的存储器所花的时间要少得多
造成差异的原因在于内存的组织和接口分布在不同位置
Linux 物理内存组织结构
Linux把物理内存划分为三个层次来管理:
- 存储节点(Node):是每个CPU对应的一个本地内存,在内核中表示为pg_*data_*t的实例。因为CPU被划分为多个节点,内存被划分为簇,每个CPU都对应一个本地物理内存,即一个CPU Node对应一个内存簇bank,即每个内存簇被认为是一个存储节点。在UMA结构下,只存在一个存储节点。
- 内存域(Zone):每个物理内存节点Node被划分为多个内存域, 用于表示不同范围的内存,内核可以使用不同的映射方式映射物理内存。
- 页面(Page):各个内存域都关联一个数组,用来组织属于该内存域的物理内存页(页帧)。页面是最基本的页面分配的单位。
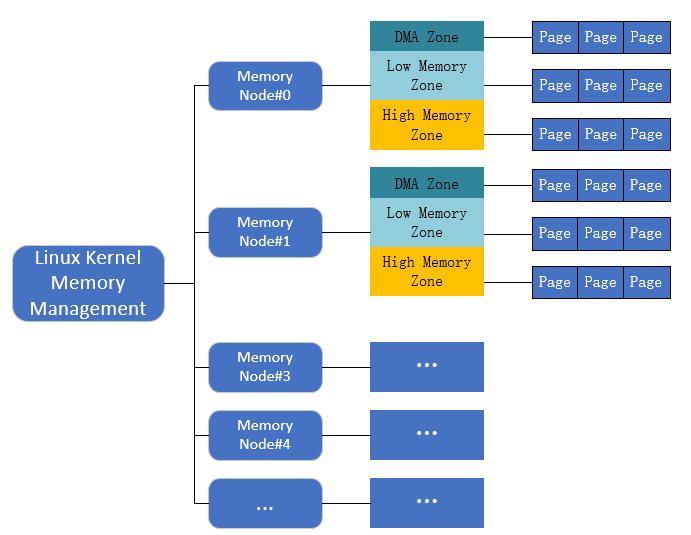
内核对UMA和NUMA 使用相同的数据结构,因此对不同形式的内存布局,各个算法没什么区别,在UMA系统上,相当于只有一个NUMA节点(只需一个pg_data_t结构体来描述),内存管理的其他代码都将内存统一当成NUMA系统的特例看待。
NODE
在分配一个页面时, Linux采用节点局部分配的策略, 从最靠近运行中的CPU的节点分配内存, 由于进程往往是在同一个CPU上运行, 因此从当前节点得到的内存很可能被用到
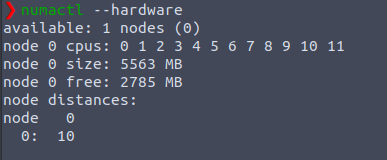
一个节点使用 pglist_data 结构进行描述,该结构定义于 /include/linux/mmzone.h 中,在linux系统中可以用numactl命令来查看系统node信息(默认不安装)
sudo apt install numactl安装即可
1 | typedef struct pglist_data { |
首先, 内存被划分为结点. 每个节点关联到系统中的一个处理器, 内核中表示为
pg_data_t的实例. 系统中每个节点被链接到一个以NULL结尾的pgdat_list链表中<而其中的每个节点利用pg_data_tnode_next字段链接到下一节.而对于PC这种UMA结构的机器来说, 只使用了一个成为contig_page_data的静态pg_data_t结构.接着各个节点又被划分为内存管理区域, 一个管理区域通过struct zone_struct描述, 其被定义为zone_t, 用以表示内存的某个范围, 低端范围的16MB被描述为ZONE_DMA, 某些工业标准体系结构中的(ISA)设备需要用到它, 然后是可直接映射到内核的普通内存域ZONE_NORMAL,最后是超出了内核段的物理地址域ZONE_HIGHMEM, 被称为高端内存. 是系统中预留的可用内存空间, 不能被内核直接映射.
ZONE
为什么node要分为多个zone?
NUMA结构下, 每个处理器CPU与一个本地内存直接相连, 而不同处理器之前则通过总线进行进一步的连接, 因此相对于任何一个CPU访问本地内存的速度比访问远程内存的速度要快, 而Linux为了兼容NUMAJ结构, 把物理内存相依照CPU的不同node分成簇, 一个CPU-node对应一个本地内存pgdata_t.
这样已经很好的表示物理内存了, 在一个理想的计算机系统中, 一个页框就是一个内存的分配单元, 可用于任何事情:存放内核数据, 用户数据和缓冲磁盘数据等等. 任何种类的数据页都可以存放在任页框中, 没有任何限制.
但是Linux内核又把各个物理内存节点分成个不同的管理区域zone, 这是为什么呢?
因为实际的计算机体系结构有硬件的诸多限制, 这限制了页框可以使用的方式. 尤其是, Linux内核必须处理80x86体系结构的两种硬件约束.
- ISA总线的直接内存存储DMA处理器有一个严格的限制 : 他们只能对RAM的前16MB进行寻址
- 在具有大容量RAM的现代32位计算机中, CPU不能直接访问所有的物理地址, 因为线性地址空间太小, 内核不可能直接映射所有物理内存到线性地址空间, 我们会在后面典型架构(x86)上内存区域划分详细讲解x86_32上的内存区域划分
因此Linux内核对不同区域的内存需要采用不同的管理方式和映射方式, 因此内核将物理地址或者成用zone_t表示的不同地址区域
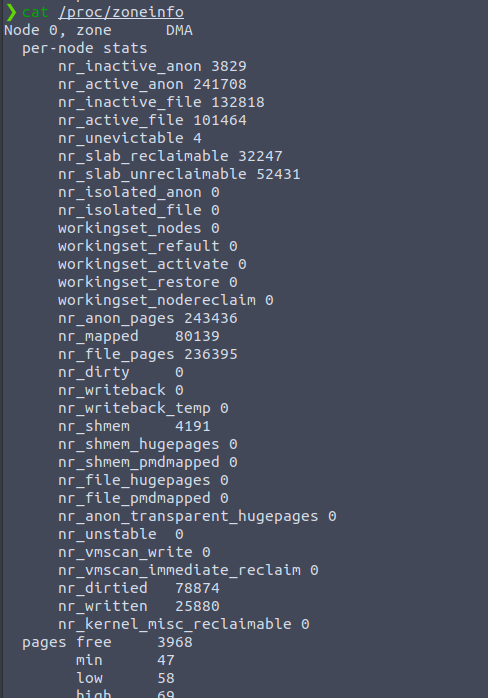
对于x86-64架构或MIPS架构,除硬件外设访问的物理区间上的内存域为ZONE_DMA除外,其余都为ZONE_NORMAL类型,每个内存域内部则记录了所覆盖的页帧情况并用buddy system 来管理本内存域内部的空闲页帧,可以通过cat /proc/zoneinfo 命令查看系统的zone相关信息
zone域用zone结构体描述,该结构体定义于 /include/linux/mmzone.h 中,如下:
1 | struct zone { |
由于多cpu多核的发展,当多个cpu需对一个zone操作时,容易造成条件竞争,频繁加解锁操作又过于消耗时间,故引入了per_cpu_pages结构,为每个cpu都准备一个单独的页面仓库
```c
struct per_cpu_pages {
int count; /* 链表所包含的页数目 /
int high; / 高水位线 /
int batch; / chunk size for buddy add/remove /
short free_factor; / batch scaling factor during free /
#ifdef CONFIG_NUMA
short expire; / When 0, remote pagesets are drained */
#endif/* Lists of pages, one per migrate type stored on the pcp-lists */ struct list_head lists[NR_PCP_LISTS];};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
- > 参考:https://arttnba3.cn/2021/11/28/OS-0X02-LINUX-KERNEL-MEMORY-5.11-PART-I/#0x01-struct-page%EF%BC%9A%E9%A1%B5
>
> 该结构体会被存放在每个 CPU 自己独立的 `.data..percpu` 段中,以 CPU0 为例,结构如下图所示
>
> [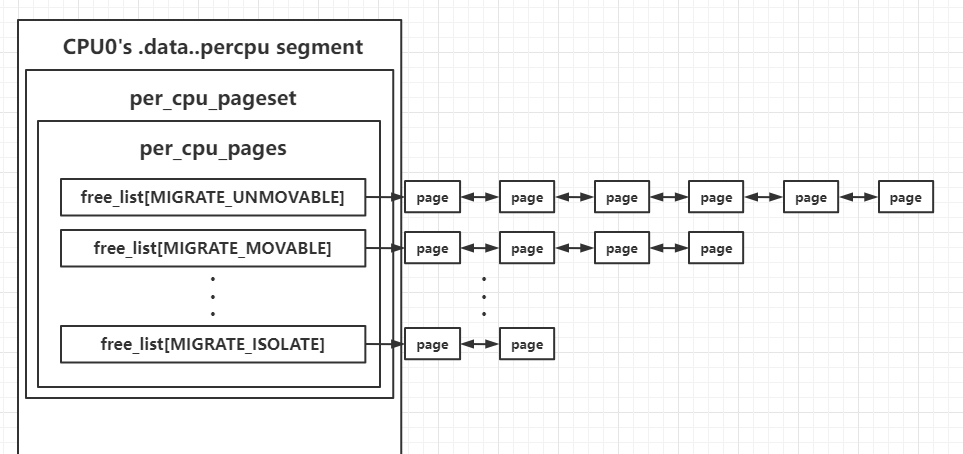](https://i.loli.net/2021/12/03/1dCZA3IDpUK2xYg.png)
- 所有空闲页帧由buddy system 通过free_area[MAX_ORDER] 来管理,并按照连续的空闲页面区间大小组织成多个队列。
> 关于zone_padding, 请看这位博主的文章https://www.cnblogs.com/still-smile/p/11564598.html
>
> 以下是摘抄:
>
> 该结构比较特殊的地方是它由ZONE_PADDING分隔的几个部分. 这是因为堆zone结构的访问非常频繁. 在多处理器系统中, 通常会有不同的CPU试图同时访问结构成员. 因此使用锁可以防止他们彼此干扰, 避免错误和不一致的问题. 由于内核堆该结构的访问非常频繁, 因此会经常性地获取该结构的两个自旋锁zone->lock和zone->lru_lock
>
> > 由于 `struct zone` 结构经常被访问到, 因此这个数据结构要求以 `L1 Cache` 对齐. 另外, 这里的 `ZONE_PADDING( )` 让 `zone->lock` 和 `zone_lru_lock` 这两个很热门的锁可以分布在不同的 `Cahe Line` 中. 一个内存 `node` 节点最多也就几个 `zone`, 因此 `zone` 数据结构不需要像 `struct page` 一样关心数据结构的大小, 因此这里的 `ZONE_PADDING( )` 可以理解为用空间换取时间(性能). 在内存管理开发过程中, 内核开发者逐渐发现有一些自选锁竞争会非常厉害, 很难获取. 像 `zone->lock` 和 `zone->lru_lock` 这两个锁有时需要同时获取锁. 因此保证他们使用不同的 `Cache Line` 是内核常用的一种优化技巧.
>
> 那么数据保存在CPU高速缓存中, 那么会处理得更快速. 高速缓冲分为行, 每一行负责不同的内存区. 内核使用ZONE_PADDING宏生成"填充"字段添加到结构中, 以确保每个自旋锁处于自身的缓存行中
>
> ZONE_PADDING宏定义在[nclude/linux/mmzone.h?v4.7, line 105](http://lxr.free-electrons.com/source/include/linux/mmzone.h?v4.7#L105)
>
>
>
> ```c
> /*
> * zone->lock and zone->lru_lock are two of the hottest locks in the kernel.
> * So add a wild amount of padding here to ensure that they fall into separate
> * cachelines. There are very few zone structures in the machine, so space
> * consumption is not a concern here.
> */
> #if defined(CONFIG_SMP)
> struct zone_padding
> {
> char x[0];
> } ____cacheline_internodealigned_in_smp;
> #define ZONE_PADDING(name) struct zone_padding name;
>
> #else
> #define ZONE_PADDING(name)
> #endif
内核还用了____cacheline_internodealigned_in_smp,来实现最优的高速缓存行对其方式.
2
3
4
5
6
7
8
zone flags: 定义于 include/linux/mmzone.h
不知道为啥只有两个…
1 | enum zone_flags { |
在一些低的版本是这样
1 | enum zone_flags |
| flag标识 | 描述 |
|---|---|
| ZONE_RECLAIM_LOCKED | 防止并发回收, 在SMP上系统, 多个CPU可能试图并发的回收亿i个内存域. ZONE_RECLAIM_LCOKED标志可防止这种情况: 如果一个CPU在回收某个内存域, 则设置该标识. 这防止了其他CPU的尝试 |
| ZONE_OOM_LOCKED | 用于某种不走运的情况: 如果进程消耗了大量的内存, 致使必要的操作都无法完成, 那么内核会使徒杀死消耗内存最多的进程, 以获取更多的空闲页, 该标志可以放置多个CPU同时进行这种操作 |
| ZONE_CONGESTED | 标识当前区域中有很多脏页 |
| ZONE_DIRTY | 用于标识最近的一次页面扫描中, LRU算法发现了很多脏的页面 |
| ZONE_WRITEBACK | 最近的回收扫描发现有很多页在写回 |
| ZONE_FAIR_DEPLETED | 公平区策略耗尽(没懂) |
type:定义于 include/linux/mmzone.h
1 | enum zone_type { |
| 管理内存域 | 描述 |
|---|---|
| ZONE_DMA | 标记了适合DMA的内存域. 该区域的长度依赖于处理器类型. 这是由于古老的ISA设备强加的边界. 但是为了兼容性, 现代的计算机也可能受此影响 |
| ZONE_DMA32 | 标记了使用32位地址字可寻址, 适合DMA的内存域. 显然, 只有在53位系统中ZONE_DMA32才和ZONE_DMA有区别, 在32位系统中, 本区域是空的, 即长度为0MB, 在Alpha和AMD64系统上, 该内存的长度可能是从0到4GB |
| ZONE_NORMAL | 标记了可直接映射到内存段的普通内存域. 这是在所有体系结构上保证会存在的唯一内存区域, 但无法保证该地址范围对应了实际的物理地址. 例如, 如果AMD64系统只有两2G内存, 那么所有的内存都属于ZONE_DMA32范围, 而ZONE_NORMAL则为空 |
| ZONE_HIGHMEM | 标记了超出内核虚拟地址空间的物理内存段, 因此这段地址不能被内核直接映射 |
| ZONE_MOVABLE | 内核定义了一个伪内存域ZONE_MOVABLE, 在防止物理内存碎片的机制memory migration中需要使用该内存域. 供防止物理内存碎片的极致使用 |
| ZONE_DEVICE | 为支持热插拔设备而分配的Non Volatile Memory非易失性内存 |
| MAX_NR_ZONES | 充当结束标记, 在内核中想要迭代系统中所有内存域, 会用到该常亮 |
PAGE
分析了节点和内存域后,讨论他们的基本元素-page,每个物理页帧有一个page结构体描述,为了节省内存空间,其定义中使用了大量的联合体。所有的page构成一个全局数组并由node和zone管理,zone中的空闲页帧形成了buddy system。而当页帧用于小数据对象时,由slab/slub 系统所管理,用于文件页缓存时由address_space管理。
必须要理解的是,page结构于物理页相关,而并非与虚拟页相关,故该结构体对页的描述只是短暂的,内核仅仅用这个数据结构来描述当前时刻在相关物理页中所存放的东西,这个数据结构的目的在于描述物理内存本身,而不是描述包含在其中的数据。
page结构体定义于/include/linux/mm_types.h ,如下:
1 | struct page { |
整页使用方式,该种情况也存在两种页,一种是直接映射虚拟地址空间的匿名页(Anonymous Page),另一种则是用于关联文件、然后再和虚拟地址空间建立映射的页,称之为内存映射文件(Memory-mapped File)。对于该种模式,会使用联合里的以下变量
struct address_space *mapping :用于内存映射,如果是匿名页,最低位为 1;如果是映射文件,最低位为 0
pgoff_t index :映射区的偏移量
atomic_t _mapcount:指向该页的页表数
struct list_head lru :表示这一页应该在一个链表上,例如这个页面被换出,就在换出页的链表中;
compound 相关的变量用于复合页(Compound Page),就是将物理上连续的两个或多个页看成一个独立的大页。
小块内存使用方式。在很多情况下,我们只需要使用少量内存,因此采用了slab allocator技术用于分配小块内存slab。它的基本原理是从内存管理模块申请一整块页,然后划分成多个小块的存储池,用复杂的队列来维护这些小块的状态(状态包括:被分配了 / 被放回池子 / 应该被回收)。也正是因为 slab allocator 对于队列的维护过于复杂,后来就有了一种不使用队列的分配器 slub allocator,但是里面还是用了很多 带有slab的API ,因为它保留了 slab 的用户接口,可以看成 slab allocator 的另一种实现。该种模式会使用联合里的以下变量
s_mem :正在使用的 slab 的第一个对象
freelist :池子中的空闲对象
rcu_head :需要释放的列表
小块内存分配器slob,非常简单,常用于小型嵌入式系统
mapping指定了页帧所在的地址空间, index是页帧在映射内部的偏移量. 地址空间是一个非常一般的概念. 例如, 可以用在向内存读取文件时. 地址空间用于将文件的内容与装载数据的内存区关联起来. mapping不仅能够保存一个指针, 而且还能包含一些额外的信息, 用于判断页是否属于未关联到地址空间的某个匿名内存区.
- 如果mapping = 0,说明该page属于交换高速缓存页(swap cache);当需要使用地址空间时会指定交换分区的地址空间swapper_space。
- 如果mapping != 0,第0位bit[0] = 0,说明该page属于页缓存或文件映射,mapping指向文件的地址空间address_space。
- 如果mapping != 0,第0位bit[0] != 0,说明该page为匿名映射,mapping指向struct anon_vma对象。
通过mapping恢复anon_vma的方法:anon_vma = (struct anon_vma *)(mapping - PAGE_MAPPING_ANON)。
pgoff_t index是该页描述结构在地址空间radix树page_tree中的对象索引号即页号, 表示该页在vm_file中的偏移页数, 其类型pgoff_t被定义为unsigned long即一个机器字长.
pageflags 位于include/linux/page-flags.h
1 | enum pageflags { |
Linux 三种内存模型
这里有一篇讲的很好的文章 : https://zhuanlan.zhihu.com/p/503695273
Linux 有三种内存模型,定义于 include/asm-generic/memory_model.h ,一个简单的概览:
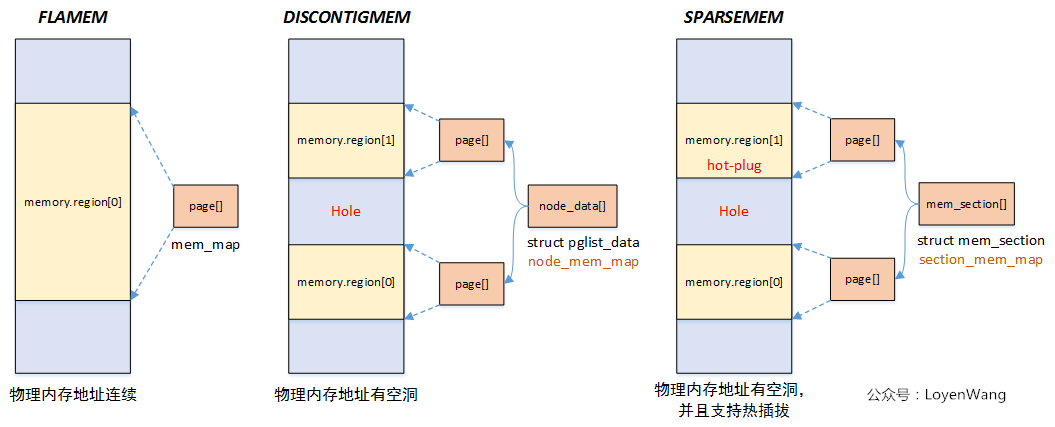
这是早期的,现在有一个SPARSEMEM_VMEMMAP,没有Discontiguous,这玩意很快就被替代了 所以不讲了
2008年以后,SPARSEMEM_VMEMMAP 成为 x86-64 唯一支持的内存模型
为什么要讲到这个,因为page结构体的存储和内存模型十分相关,从源码中就能窥知一二

内存模型在编译时就会被确定下来
从page结构体到物理页框
既然我们用page 结构体描述 物理页框,那我们怎么知道page结构体描述的是哪个物理页呢,我们通过page结构体转化成PFN 来实现。
PFN 即 page frame number 物理页框号,是针对物理内存而言的,将物理内存分成由每个page size页框构成的区域,并给每个page 编号,这个编号就是 PFN。假设物理内存从0地址开始,那么PFN等于0的那个页帧就是0地址(物理地址)开始的那个page。假设物理内存从x地址开始,那么第一个页帧号码就是(x>>PAGE_SHIFT)。
但是由于物理内存映射的关系,物理内存的0地址对应到到系统上不一定是物理地址的0,如果由物理内存基地址(取决于物理内存映射)的话,在系统中 pfn的值 应该等于 (physical address - memory base address) >> 12 。
FlATMEM:
平坦内存模型:由一个全局数组mem_map 存储 struct page,直接线性映射到实际的物理内存
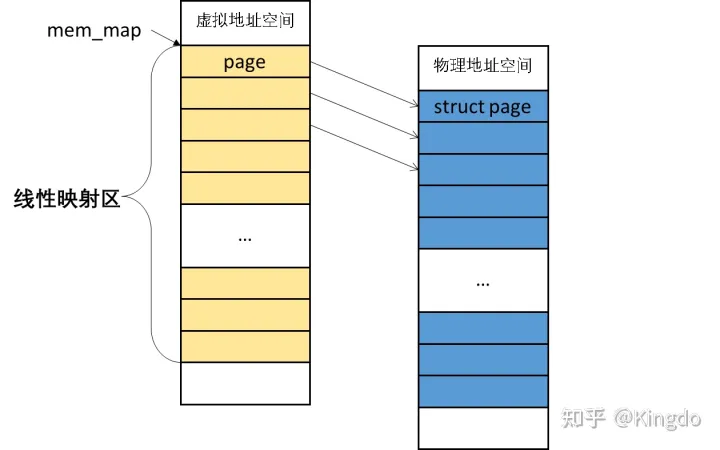
page与pfn的转化:
此时pfn直接理解为数组索引值即可
1 | #define __pfn_to_page(pfn) (mem_map + ((pfn) - ARCH_PFN_OFFSET)) |
ARCH_PFN_OFFSET 即上面所说的真实物理内存基地址
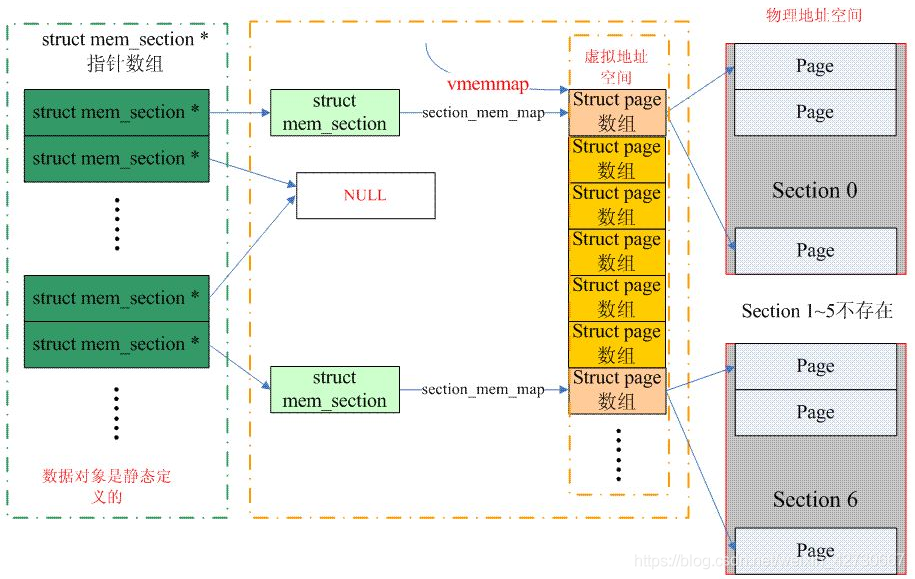
SPARSEMEM
离散内存模型
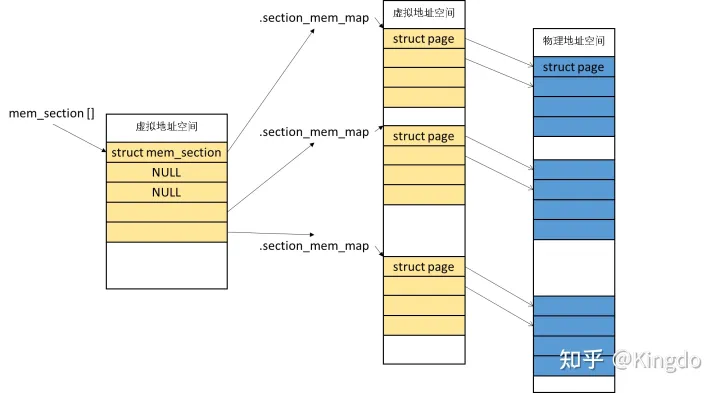
内存被分为一个个Section,每个Section包含一个sturct page 数组,这样每个数组就不用顺序存放了,结局了热插拔问题。而所有的section又由一个统一的mem_section 数组管理。
以x86为例,定义于 /arch/x86/include/asm/sparsemem.h
1 | #ifdef CONFIG_X86_32 |
可以看到section最大值为128MB,简单计算一下(2 ^ (MAX_PHYSMEM_BITS - SECTION_SIZE_BITS))会发现如果这样的话mem_section的数组大小会非常大
解决方案:mem_section 也是可以动态分配的,给定CONFIG_SPARSEMEM_EXTREME 参数,就可以实现二级数组,整个mem_section都是动态分配的
1 | #define __page_to_pfn(pg) \ |
page_to_section 可以获得page所在section,page在该section的索引放在page.flags中
__nr_to_section(__sec),就是根据section_id 找到从mem_section数组中找到指定的section
__section_mem_map_addr返回mem_section.section_mem_map
mem_section.section_mem_map 存储的为 page 数组与 PFN 的差值
SPARSEMEM_VMEMMAP
SPARSEMEM有个缺点就是 page 结构体需要存储section id ,这会由不晓得内存耗费
偷点图
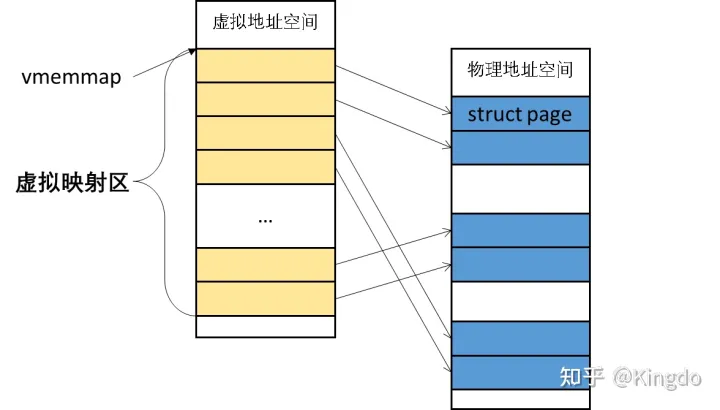
SPARSEMEM_VMEMMAP是虚拟映射,走页表
将所有的mem_section中page 都抽象到一个虚拟数组vmemmap,这样在进行struct page *和pfn转换时,之间使用vmemmap数组即可,如下转换(位于include\asm-generic\memory_model.h)
1 | #define __pfn_to_page(pfn) (vmemmap + (pfn)) |
效率高多了
slab相关
在早期的版本中,在 page 结构体中专门有着一个匿名结构体用于存放与 slab 相关的成员
1 | struct { /* 供 slab, slob and slub 使用 */ |
我阅读的5.17版本的源码中却没有,查看了commit,发现在一月的时候有了这样的改动

1 | mm: Remove slab from struct page |
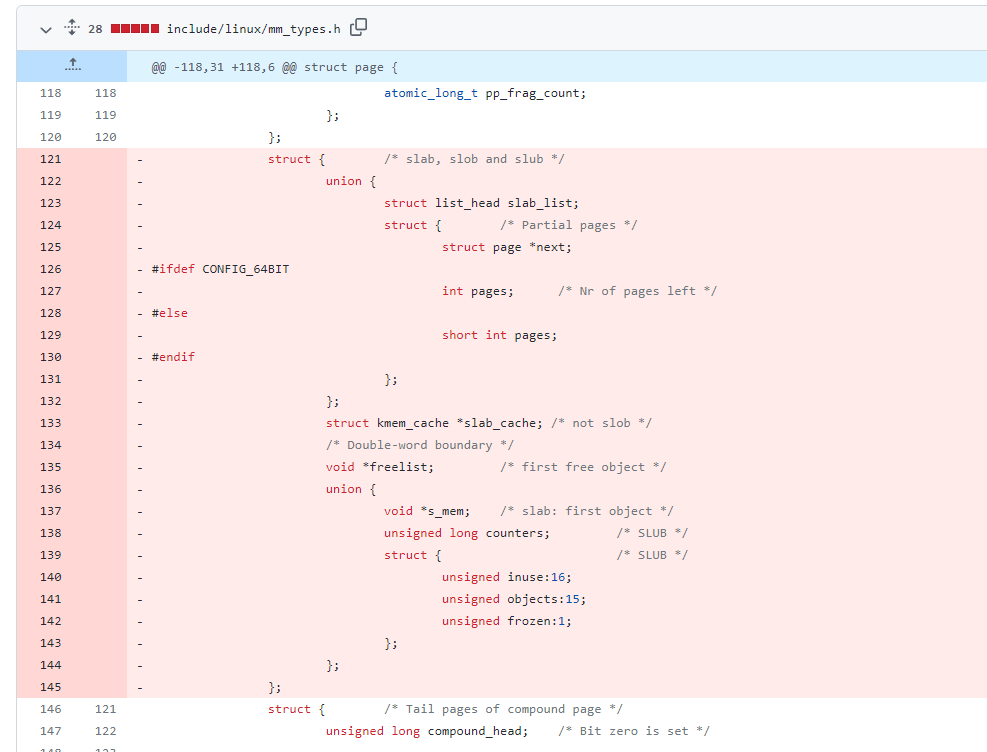
相对的 ,slab分配器也有了它单独的结构体type

具体的在 slab.h 中
1 | struct slab { |
也新增了不少slab操作相关的函数接口
注释也变成了
1 | SLUB uses cmpxchg_double() to atomically update its freelist and counters.That requires that freelist & counters in struct slab be adjacent and double-word aligned. Because struct slab currently just reinterprets the bits of struct page, we align all struct pages to double-word boundaries,and ensure that 'freelist' is aligned within struct slab. |
LRU链表
LRU即Least Recently Used,对于整个内存回收而言,LRU是十分关键的数据机构,整个内存回收,实际上就是处理lru链表的收缩。
lru链表并非在系统中只有一个,而是每个zone有一个,每个memcg在每个zone上也有一个,结构为list_head 是内核,是内核通用链表构。
哪些页面可以被回收?
磁盘高速缓存的页面(包括文件映射的页面)都是可以被丢弃并回收的。但是如果页面是脏页面,则丢弃之前必须将其写回磁盘。
匿名映射的页面则都是不可以丢弃的,因为页面里面存有用户程序正在使用的数据,丢弃之后数据就没法还原了。相比之下,磁盘高速缓存页面中的数据本身是保存在磁盘上的,可以复现。
于是,要想回收匿名映射的页面,只好先把页面上的数据转储到磁盘,这就是页面交换(swap)。显然,页面交换的代价相对更高一些。匿名映射的页面可以被交换到磁盘上的交换文件或交换分区上(分区即是设备,设备即也是文件。所以下文统称为交换文件)。
于是,除非页面被保留或被上锁(页面标记PG_reserved/PG_locked被置位。某些情况下,内核需要暂时性地将页面保留,避免被回收),所有的磁盘高速缓存页面都可回收,所有的匿名映射页面都可交换。
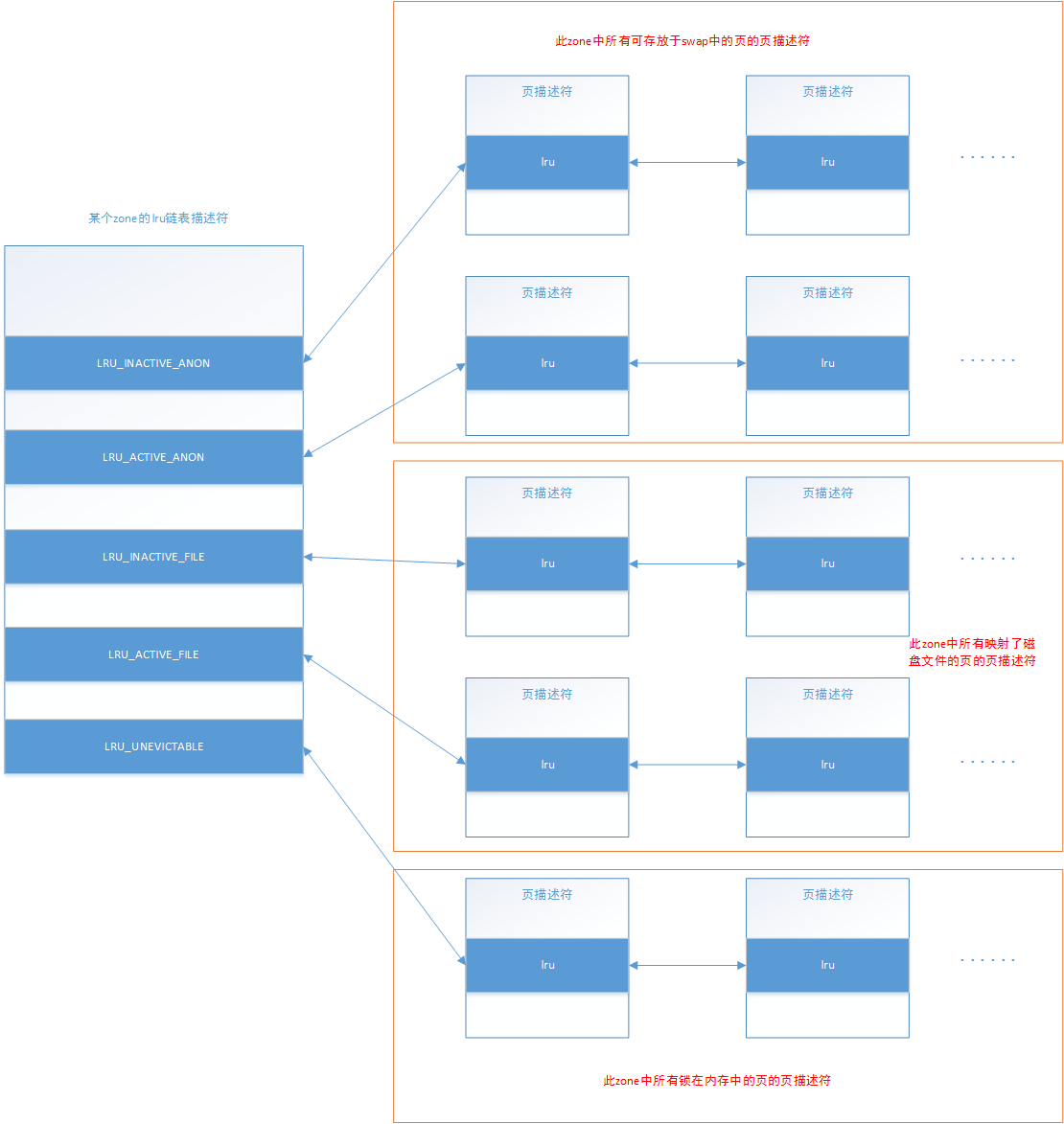
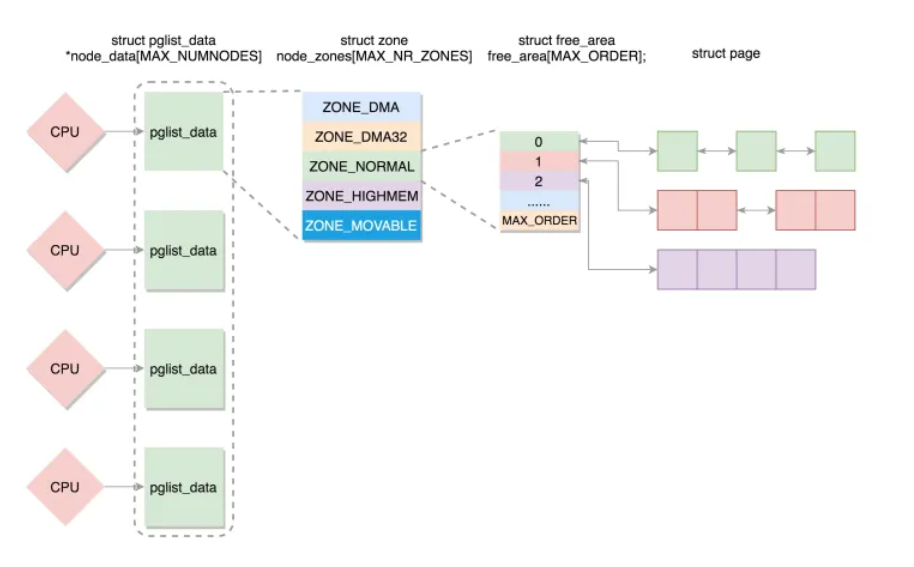
最后来一个总览图:
参考资料
https://www.cnblogs.com/MrLiuZF/p/15251906.html
https://blog.csdn.net/shulianghan/article/details/124256224
https://www.cnblogs.com/still-smile/p/11564598.html
https://blog.csdn.net/yhb1047818384/article/details/111789736
https://zhuanlan.zhihu.com/p/464770819
https://biscuitos.github.io/blog/NODEMASK/
《Linux技术内幕》- 罗秋明
《Linux内核设计与实现》-Robert Love