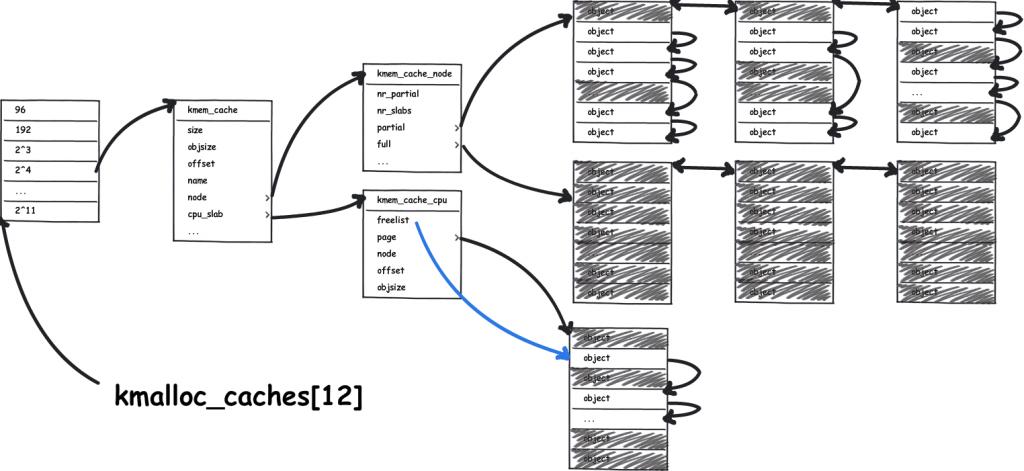
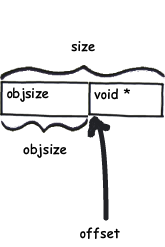
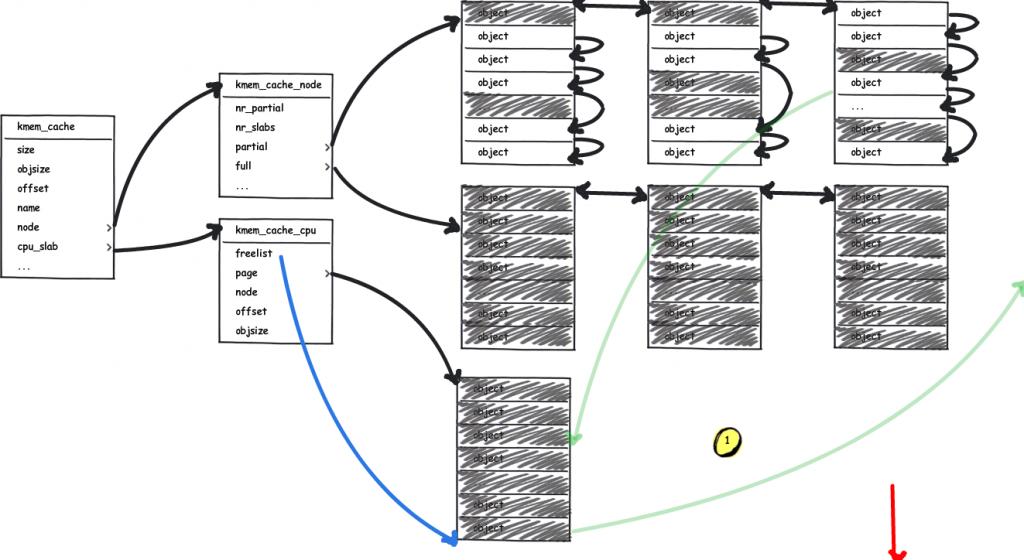
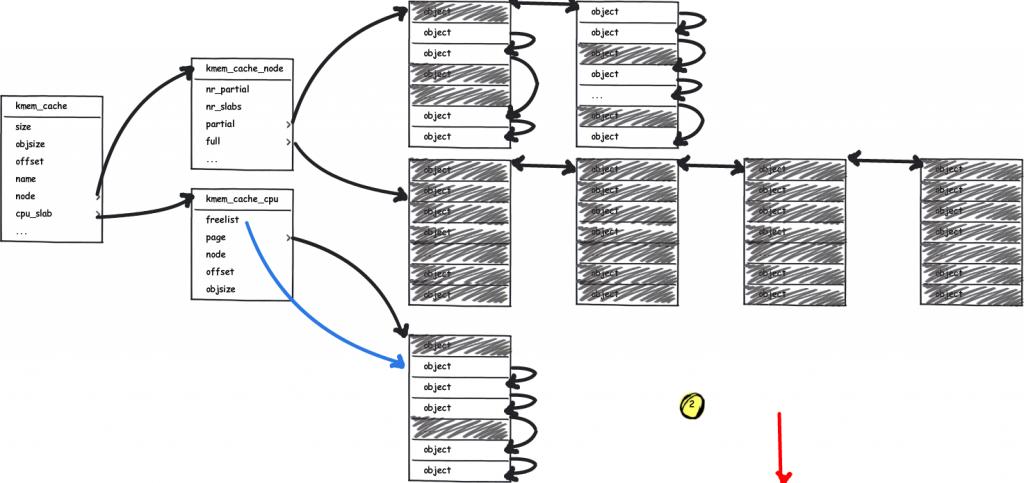
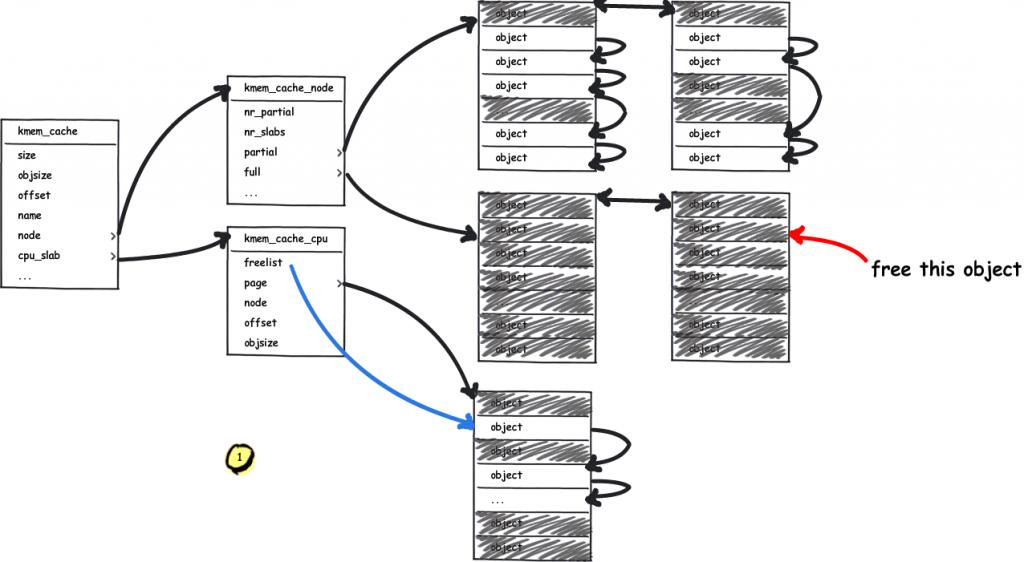
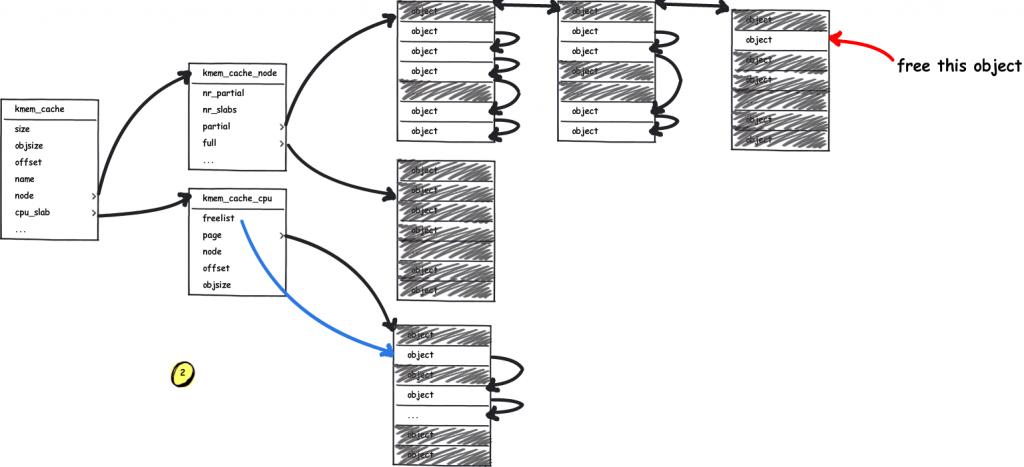
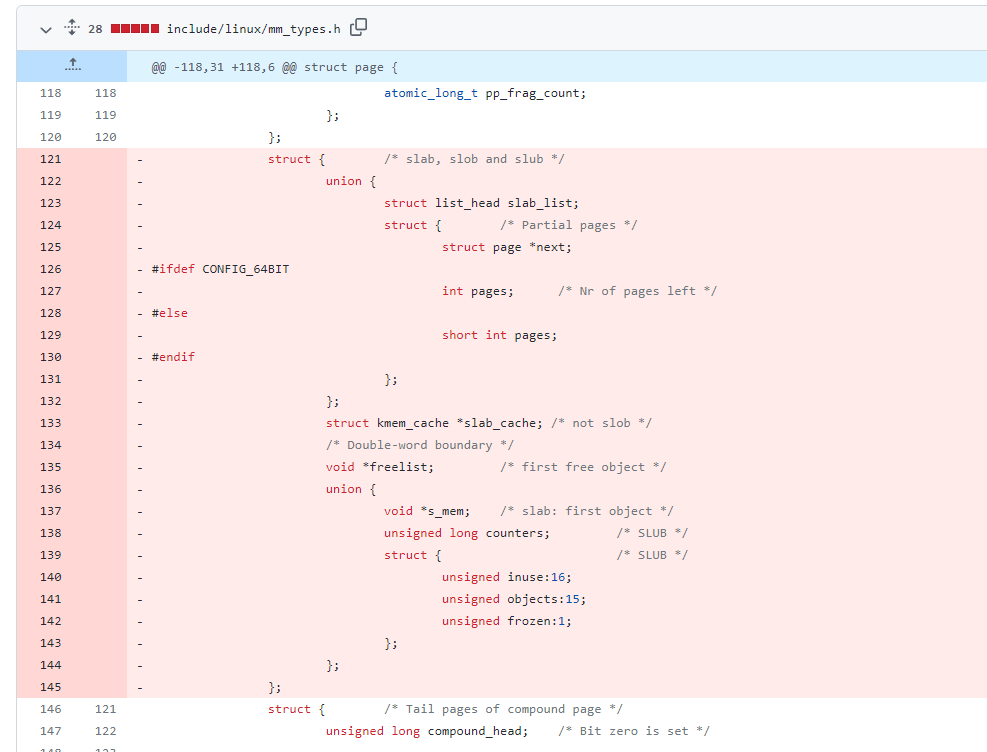
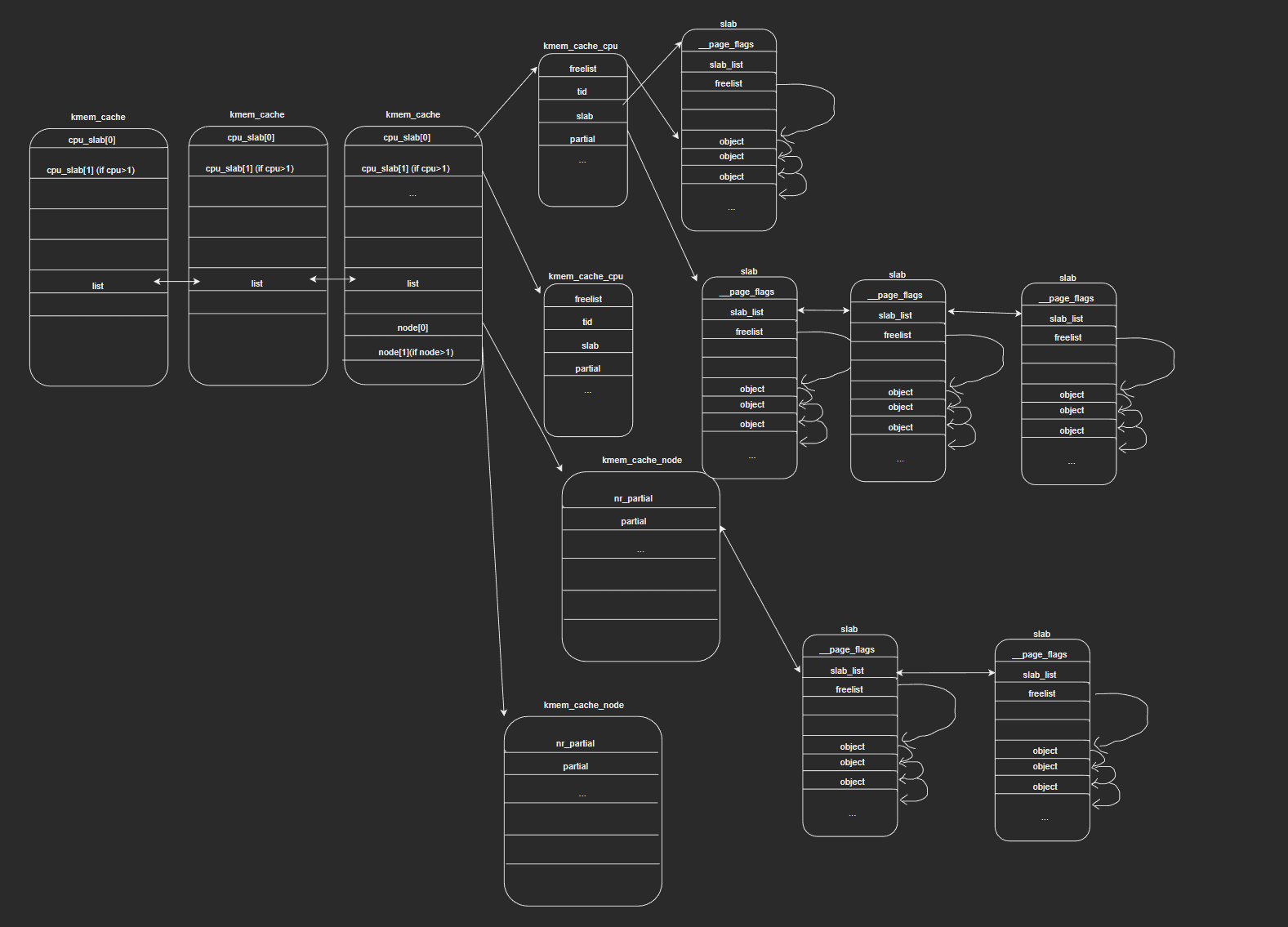
mm: Remove slab from struct page All members of struct slab can now be removed from struct page. This shrinks the definition of struct page by 30 LOC, making it easier to understand.
/* * Let the initial higher-order allocation fail under memory pressure * so we fall-back to the minimum order allocation. */ alloc_gfp = (flags | __GFP_NOWARN | __GFP_NORETRY) & ~__GFP_NOFAIL; if ((alloc_gfp & __GFP_DIRECT_RECLAIM) && oo_order(oo) > oo_order(s->min)) alloc_gfp = (alloc_gfp | __GFP_NOMEMALLOC) & ~(__GFP_RECLAIM|__GFP_NOFAIL);
slab = alloc_slab_page(s, alloc_gfp, node, oo); if (unlikely(!slab)) { oo = s->min; alloc_gfp = flags; /* * Allocation may have failed due to fragmentation. * Try a lower order alloc if possible */ slab = alloc_slab_page(s, alloc_gfp, node, oo); if (unlikely(!slab)) goto out; stat(s, ORDER_FALLBACK); }
slab->objects = oo_objects(oo);
account_slab(slab, oo_order(oo), s, flags);
slab->slab_cache = s;
kasan_poison_slab(slab);
start = slab_address(slab);
setup_slab_debug(s, slab, start);
shuffle = shuffle_freelist(s, slab); /* shuffle_freelist: if (slab->objects < 2 || !s->random_seq) return false; */ if (!shuffle) { //找到第一个object的地址 start = fixup_red_left(s, start); start = setup_object(s, slab, start); slab->freelist = start;//freelist指向第一个object //从第一个object开始,逐个初始化object链表 for (idx = 0, p = start; idx < slab->objects - 1; idx++) { next = p + s->size;//kmem_cache所存的object size(包含元数据) next = setup_object(s, slab, next); set_freepointer(s, p, next); p = next; } set_freepointer(s, p, NULL);//最后一个object的指针为NULL }
object = kfence_alloc(s, orig_size, gfpflags);//优先使用kfence_alloc 分配,貌似与kfence内存池有关,mark if (unlikely(object)) goto out;
redo: /* 必须通过这个 cpu ptr 读取 kmem_cache cpu 数据。启用抢占。我们可能会在从一个 cpu 区域读取时在 cpus 之间来回切换。只要我们在执行 cmpxchg 时再次使用原始 cpu 就没有关系。 * 我们必须保证在同一个 cpu 上检索到 tid 和 kmem_cache_cpu。我们首先读取 kmem_cache_cpu 指针并使用它来读取 tid。如果我们在两次读取之间被抢占并切换到另一个 cpu,那没关系,因为这两个 cpu 仍然与同一个 cpu 关联,稍后 cmpxchg 将验证 cpu。 */ //获得当前cpu_slab 与 tid c = raw_cpu_ptr(s->cpu_slab); tid = READ_ONCE(c->tid);
/* 这里使用的 Irqless 对象分配/释放算法取决于获取 cpu_slab 数据的顺序。 tid 应该在 c 上的任何内容之前获取,以保证与前一个 tid 关联的对象和 slab 不会与当前 tid 一起使用。如果我们先获取 tid,对象和 slab 可能与下一个 tid 关联,我们的分配/释放请求将失败。在这种情况下,我们将重试。所以,没问题。 */ //barrier内存屏障 用于保证内存访问按严格的顺序来 barrier();
/* 每个 cpu 和每个 cpu 队列上的每个操作的事务 ID 是全局唯一的。因此,他们可以保证 cmpxchg_double 出现在正确的处理器上,并且在其间的链表上没有任何操作。 */
new_slab: //获取新的slab if (slub_percpu_partial(c)) { local_lock_irqsave(&s->cpu_slab->lock, flags); if (unlikely(c->slab)) { local_unlock_irqrestore(&s->cpu_slab->lock, flags); goto reread_slab; } if (unlikely(!slub_percpu_partial(c))) { local_unlock_irqrestore(&s->cpu_slab->lock, flags); /* we were preempted and partial list got empty */ goto new_objects; }
slub_put_cpu_ptr(s->cpu_slab); slab = new_slab(s, gfpflags, node); c = slub_get_cpu_ptr(s->cpu_slab);
if (unlikely(!slab)) { slab_out_of_memory(s, gfpflags, node);//调用buddy system,分配slab returnNULL; }
/* * No other reference to the slab yet so we can * muck around with it freely without cmpxchg */ freelist = slab->freelist; slab->freelist = NULL;
stat(s, ALLOC_SLAB);
check_new_slab: //检查从node中获取的slab if (kmem_cache_debug(s)) { if (!alloc_debug_processing(s, slab, freelist, addr)) { /* Slab failed checks. Next slab needed */ goto new_slab; } else { /* * For debug case, we don't load freelist so that all * allocations go through alloc_debug_processing() */ goto return_single; } }
if (unlikely(!pfmemalloc_match(slab, gfpflags))) /* * For !pfmemalloc_match() case we don't load freelist so that * we don't make further mismatched allocations easier. */ goto return_single;
folio = virt_to_folio(x);//通过虚拟地址找到对应的物理页的folio /* folio 只是封装了 struct page 的一个容器,确保这个 page 不会是一个 tail page。因此,它可以用来以 single page 或更大的 page 为单位来指代内存区域。 * page_folio - Converts from page to folio. * @p: The page. * * Every page is part of a folio. This function cannot be called on a * NULL pointer. * * Context: No reference, nor lock is required on @page. If the caller * does not hold a reference, this call may race with a folio split, so * it should re-check the folio still contains this page after gaining * a reference on the folio. * Return: The folio which contains this page. */ if (unlikely(!folio_test_slab(folio))) { free_large_kmalloc(folio, object); return; } slab = folio_slab(folio); slab_free(slab->slab_cache, slab, object, NULL, 1, _RET_IP_); } EXPORT_SYMBOL(kfree);
slab_free 封装了do_slab_free
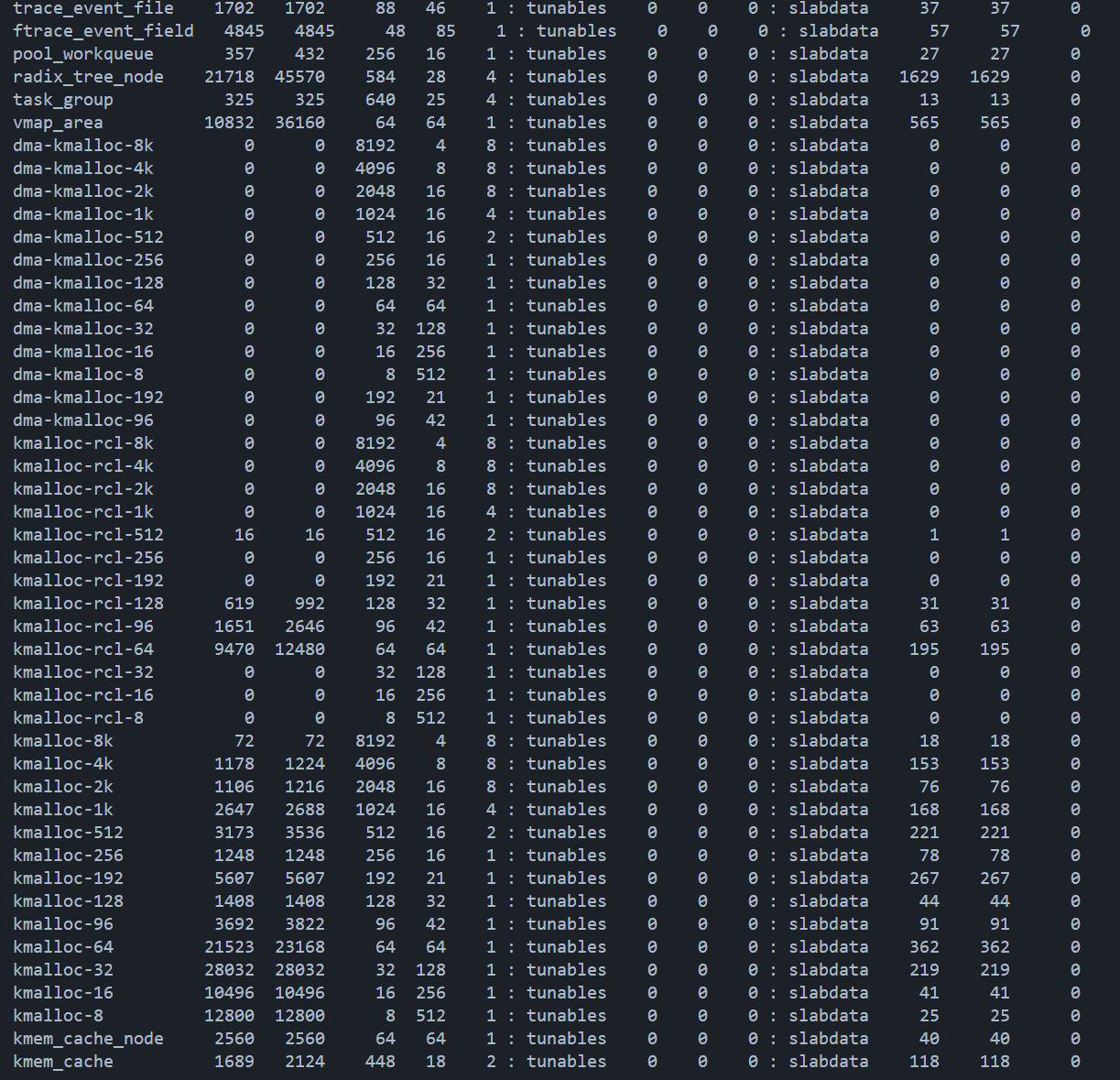
1 2 3 4 5 6 7 8 9 10 11 12
//要释放的object就是参数 void * head static __always_inline voidslab_free(struct kmem_cache *s, struct slab *slab, void *head, void *tail, int cnt, unsignedlong addr) { /* * With KASAN enabled slab_free_freelist_hook modifies the freelist * to remove objects, whose reuse must be delayed. */ if (slab_free_freelist_hook(s, &head, &tail, &cnt)) do_slab_free(s, slab, head, tail, cnt, addr); }
/* memcg_slab_free_hook() is already called for bulk free. */ if (!tail)// memcg_slab_free_hook(s, &head, 1); redo: /* * 确定当前每个 cpu slab 的 cpus。 * cpu 之后可能会发生变化。 然而,这并不重要,因为数据是通过该指针检索的。 如果我们在 cmpxchg 期间在同一个 cpu 上,那么 free 将会成功。 */ c = raw_cpu_ptr(s->cpu_slab);//获取当前cpu_cache tid = READ_ONCE(c->tid);//获取tid
/* Same with comment on barrier() in slab_alloc_node() */ barrier();//内存屏障 用于保证顺序性
if (likely(slab == c->slab)) {//当前释放的slab就是cpu_cache->slab #ifndef CONFIG_PREEMPT_RT void **freelist = READ_ONCE(c->freelist);//read once // 也就是读取了 *(cpu_cache->freelist)
* * Slow path handling. This may still be called frequently since objects * have a longer lifetime than the cpu slabs in most processing loads. * * So we still attempt to reduce cache line usage. Just take the slab * lock and free the item. If there is no additional partial slab * handling required then we can return immediately. */ staticvoid __slab_free(struct kmem_cache *s, struct slab *slab, void *head, void *tail, int cnt, unsignedlong addr)
if (kmem_cache_debug(s) && !free_debug_processing(s, slab, head, tail, cnt, addr)) return;
do { if (unlikely(n)) { spin_unlock_irqrestore(&n->list_lock, flags); n = NULL; } prior = slab->freelist; counters = slab->counters; set_freepointer(s, tail, prior); new.counters = counters; was_frozen = new.frozen; new.inuse -= cnt; if ((!new.inuse || !prior) && !was_frozen) {
if (kmem_cache_has_cpu_partial(s) && !prior) {
/* * Slab was on no list before and will be * partially empty * We can defer the list move and instead * freeze it. */ new.frozen = 1;
} else { /* Needs to be taken off a list */
n = get_node(s, slab_nid(slab)); /* * Speculatively acquire the list_lock. * If the cmpxchg does not succeed then we may * drop the list_lock without any processing. * * Otherwise the list_lock will synchronize with * other processors updating the list of slabs. */ spin_lock_irqsave(&n->list_lock, flags);
} }
} while (!cmpxchg_double_slab(s, slab, prior, counters, head, new.counters, "__slab_free"));
if (likely(!n)) {
if (likely(was_frozen)) { /* * The list lock was not taken therefore no list * activity can be necessary. */ stat(s, FREE_FROZEN); } elseif (new.frozen) { /* * If we just froze the slab then put it onto the * per cpu partial list. */ put_cpu_partial(s, slab, 1); stat(s, CPU_PARTIAL_FREE); }
return; }
if (unlikely(!new.inuse && n->nr_partial >= s->min_partial)) goto slab_empty;
/* * Objects left in the slab. If it was not on the partial list before * then add it. */ if (!kmem_cache_has_cpu_partial(s) && unlikely(!prior)) { remove_full(s, n, slab); add_partial(n, slab, DEACTIVATE_TO_TAIL); stat(s, FREE_ADD_PARTIAL); } spin_unlock_irqrestore(&n->list_lock, flags); return;
slab_empty: if (prior) { /* * Slab on the partial list. */ remove_partial(n, slab); stat(s, FREE_REMOVE_PARTIAL); } else { /* Slab must be on the full list */ remove_full(s, n, slab); }